一、无root,只想下词库就行
只想下载词库,不涉及背单词进度,不需要区分单词是否已背
https://github.com/busiyiworld/maimemo-export/releases/
墨墨背单词所有本地词库,包括联网更新的词库,不包括云词库。截止到 2023-04-18,共有词库 1224 个。直接下载即可
二、有root,想要自己提取最新词库
自行提取词库的教程在 墨墨v5.2.4已确认失效,推荐直接下载github上现成的,但是提取已背诵的单词的方法我在下面更新了
1.用你有root的安卓机,下一个MT管理器或者其他什么能访问根目录的文件管理器,直接在根目录搜索:
maimemo*.db2.找到文件,我这里是maimemo.v4_1_10.db,后面的版本号根据你自己下的什么而定,不管它,把文件传到电脑上去
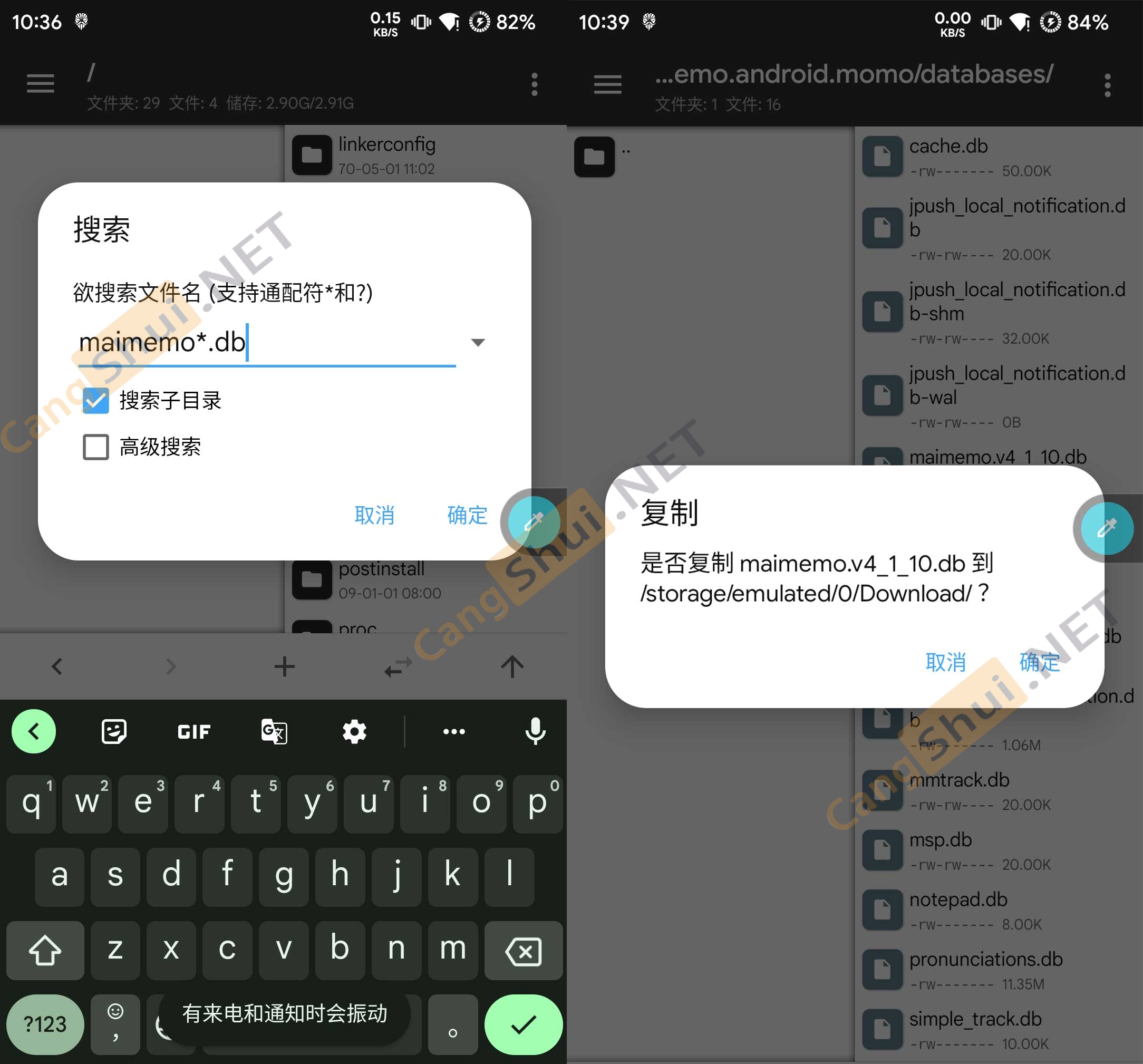
3.随便用一个能操作SQLite的软件,比如Navicat,HeidiSQL等连接这个数据库文件。
4.然后,这个数据库甚至没有任何加密,如果你会SQL,其实到这里已经可以提取了。我写了一个SQL语句,提取 考研英语大纲词汇5500 ,你可以参考一下:
SELECT chapter_id,voc_id,title,vc_vocabulary,`order`
FROM VOC_TB
INNER JOIN (
SELECT title,voc_id,chapter_id,`order`
FROM BK_VOC_TB V
INNER JOIN BK_CHAPTER_TB C ON V.chapter_id= C.id AND V.book_id IN (
SELECT original_id
FROM BK_TB
WHERE name ='考研英语大纲词汇5500')) AS tmp ON VOC_TB.original_id=tmp.voc_id
ORDER BY `order`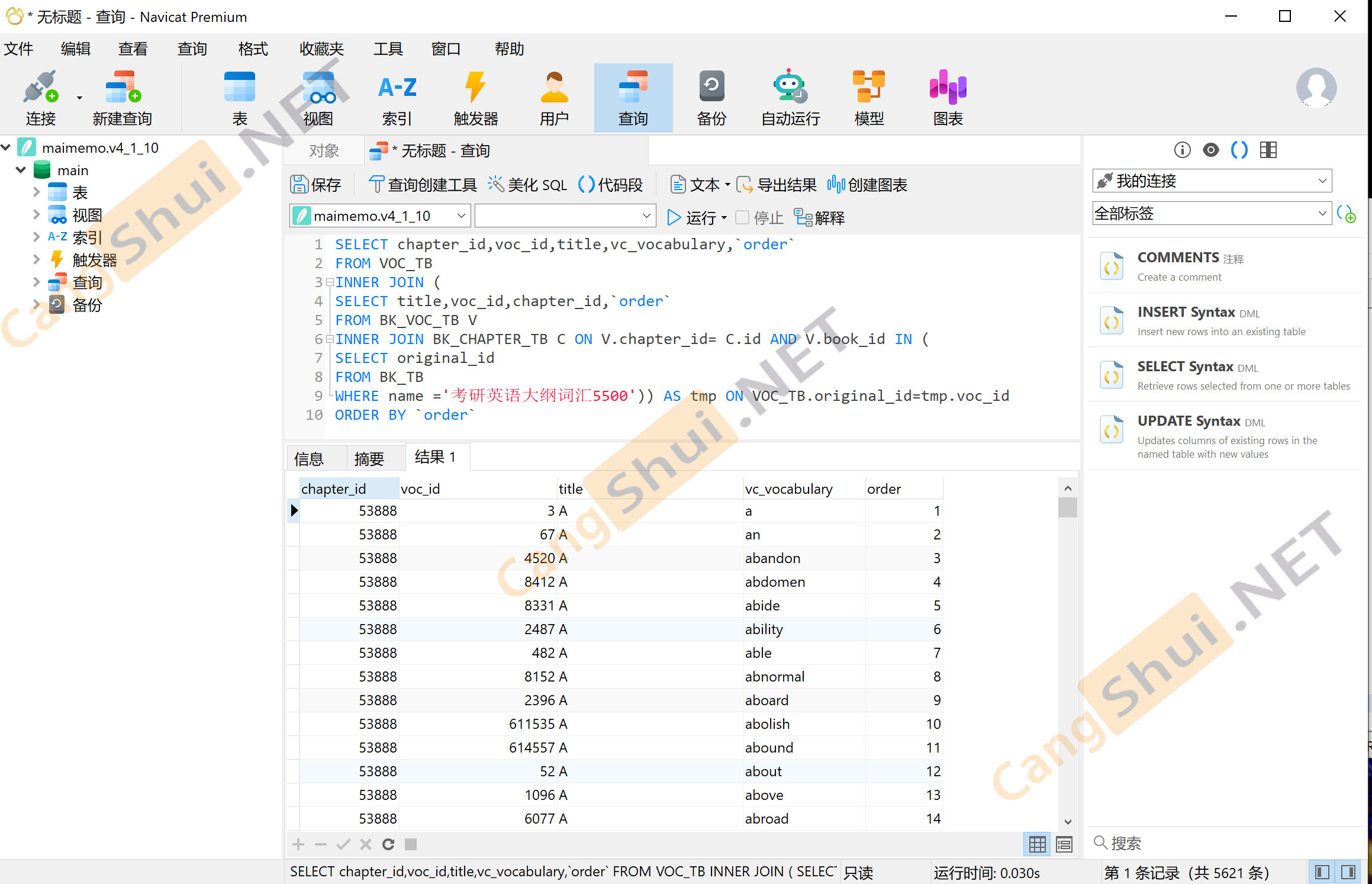
三、有root,想要提取自己背过的单词
和上面一样,也是把文件从手机里提取到电脑上用数据库软件打开,查询语句为:
v5.2.4版本是:
SELECT LSR_TB.lsr_voc_id, VOC_TB.spelling
FROM LSR_TB
JOIN VOC_TB ON LSR_TB.lsr_voc_id = VOC_TB.origin_id;
v4版本是:(已无法正常登陆V4版本,失效)
SELECT vc_vocabulary, lsr_first_study_date,lsr_last_study_date,lsr_next_study_date,lsr_frequency,lsr_add_order
FROM LSR_TB LT
INNER JOIN VOC_TB VT ON LT.lsr_new_voc_id=VT.vc_id
ORDER BY lsr_add_order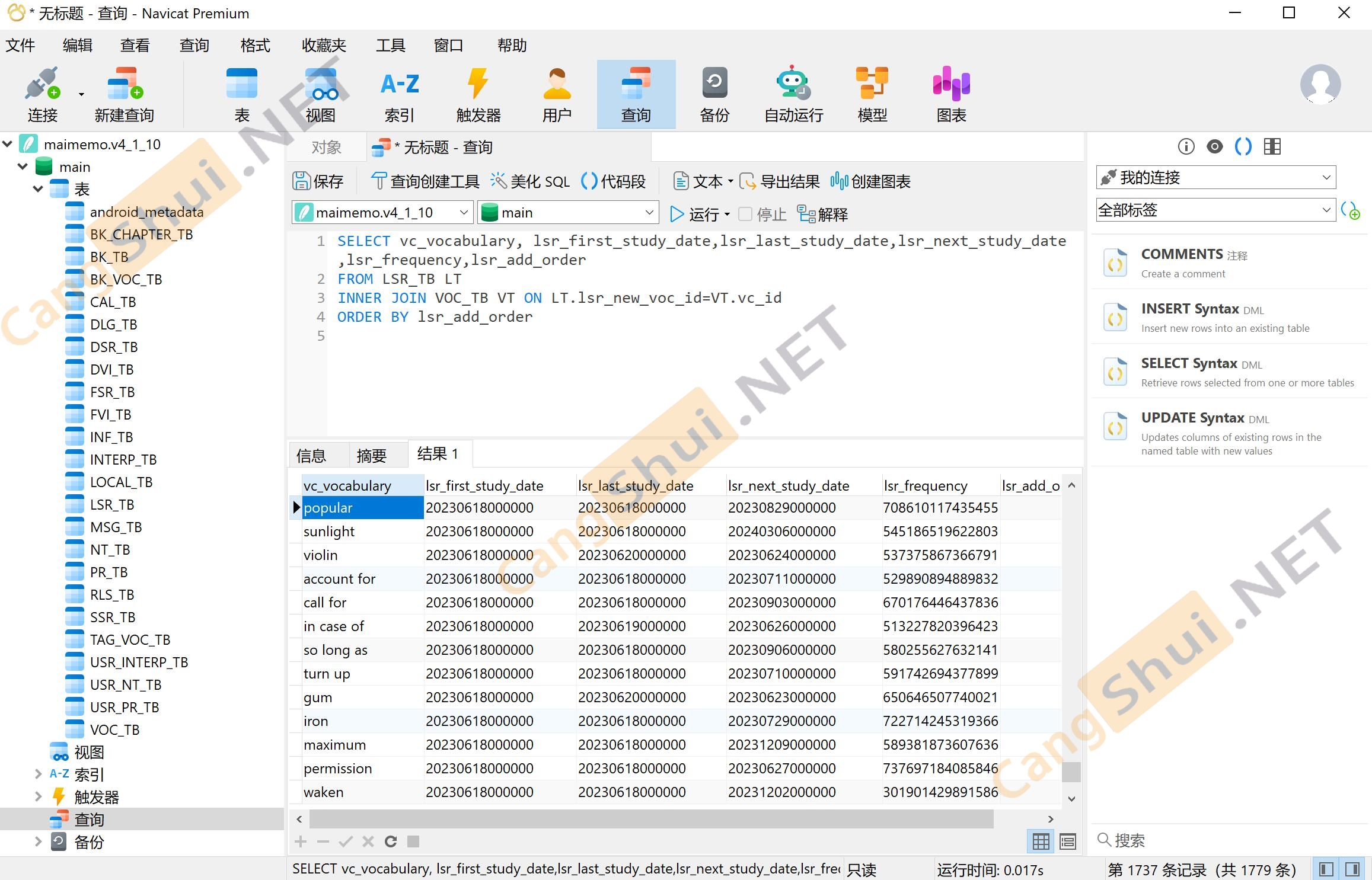
导出方法来自于 怎么把墨墨背单词里的词库导出来? – 你说什么的回答 (原回答已被删除)

有音频吗?
怎么导出该单词的词根背诵,我有1000多个单词要导出,不知道可不可以,SQL语句应该是什么