图片打包链接:pan.cangshui.net 密码: god 页面有点慢耐性等待

咦,小姐姐,还有cosplay,点进去看看。
哇,发现一个好玩的网站,好多漂亮的妹子,页面打开很流畅,点开后有的浏览页面还有好听的音乐,产品体验极佳。

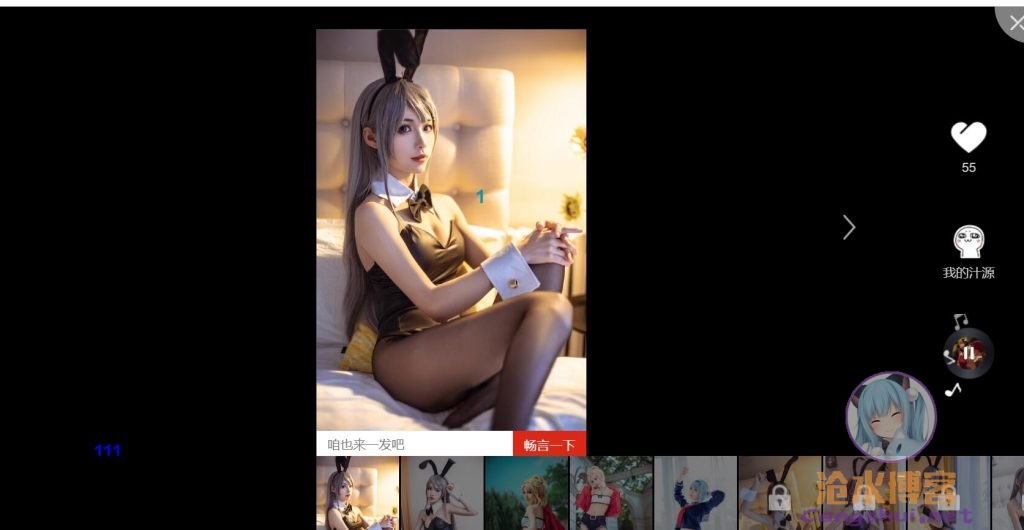
不过每组图片只能看前几张图,后面的图只能看到缩略图,如果想继续看或者打包下载得花银子,通常要1-5rmb。
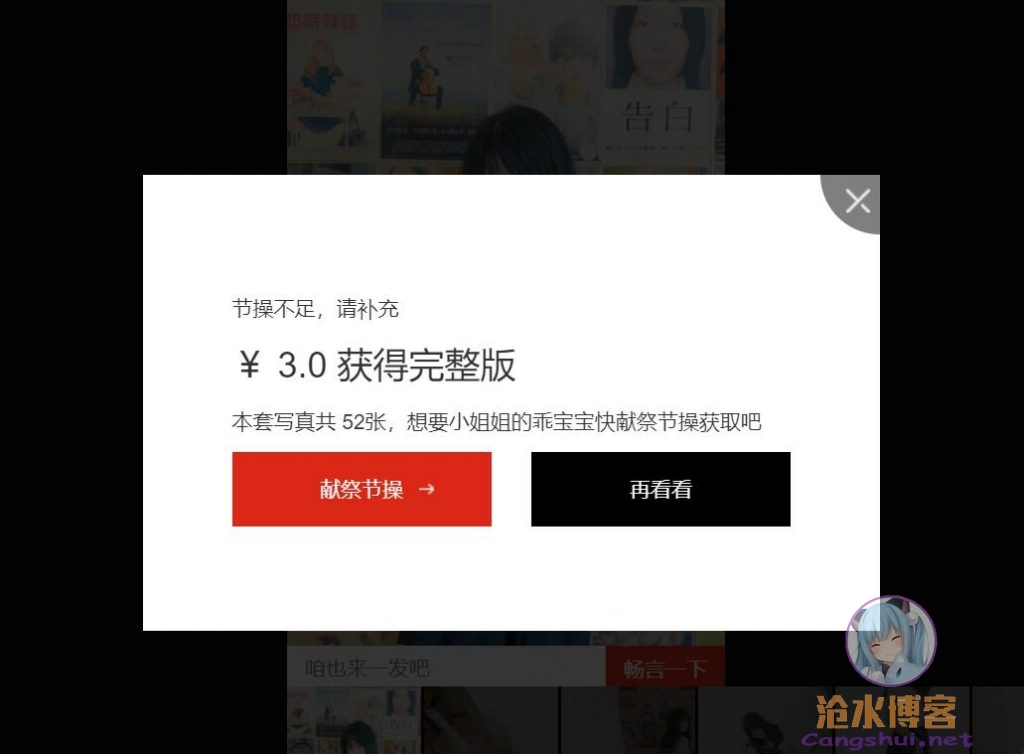
ctrlC+ctrlV几张后不乐意了,这么保存一来看不到全部图片,二来,麻烦,太麻烦了。
俗话说,妹子是第一生产力,鲁迅有云,懒人创造美好世界。
试试吧,看能不能发现点有趣的东东。首先习惯性的看看html源码,blabla一堆,头大,pass。
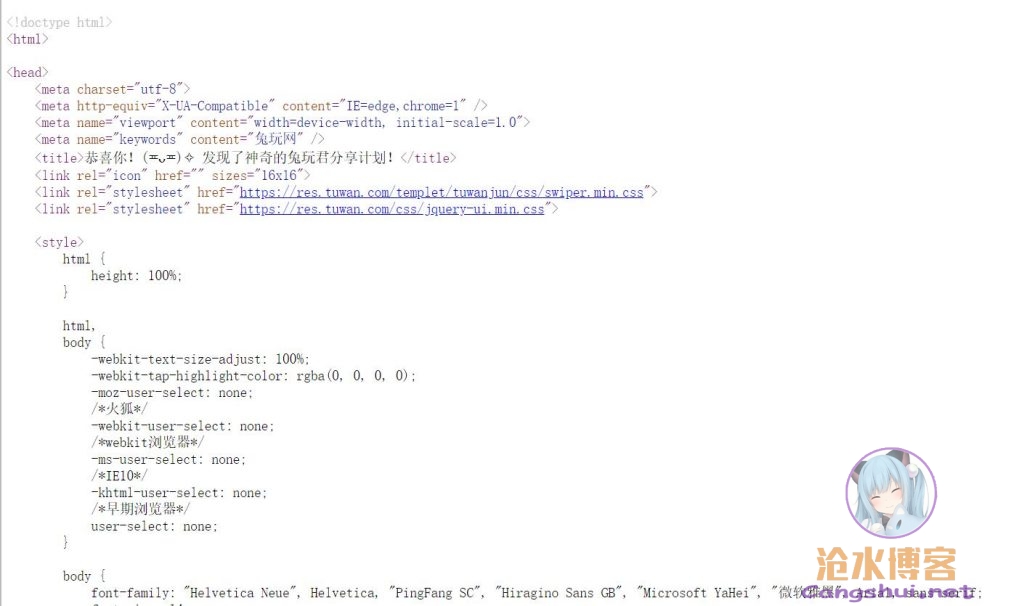
从页面源码来看,页面应该是前端渲染出来的,直接解析爬虫爬的话会比较麻烦。既然是前端渲染,那再看看请求吧,首页肯定是加载相册列表,没啥大用处,直接看加载具体某一相册的请求结果,点开某一相册,跳过图片,看看有没有什么可用的接口,果然有。
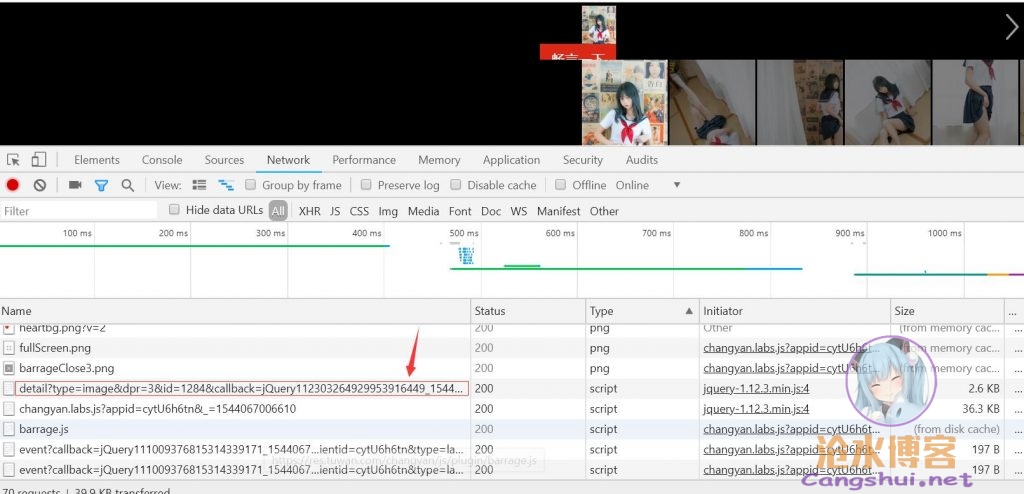
复制出来,浏览器走起,请求后返回如下信息
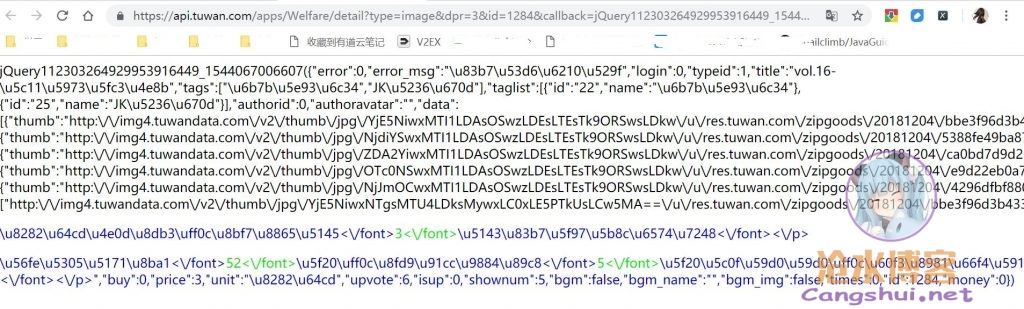
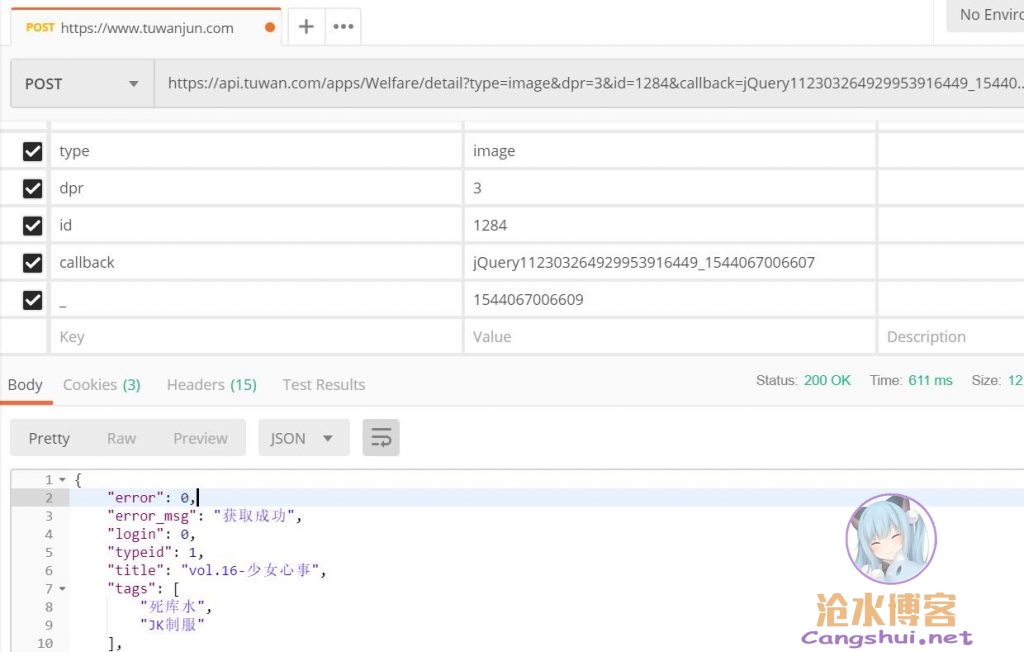
很明显是该相册的详细信息获取接口,可是怎么有些像是被编码过的东西。既然被编码了,解码出来瞧瞧,postman走起。postman顺利解析出结果
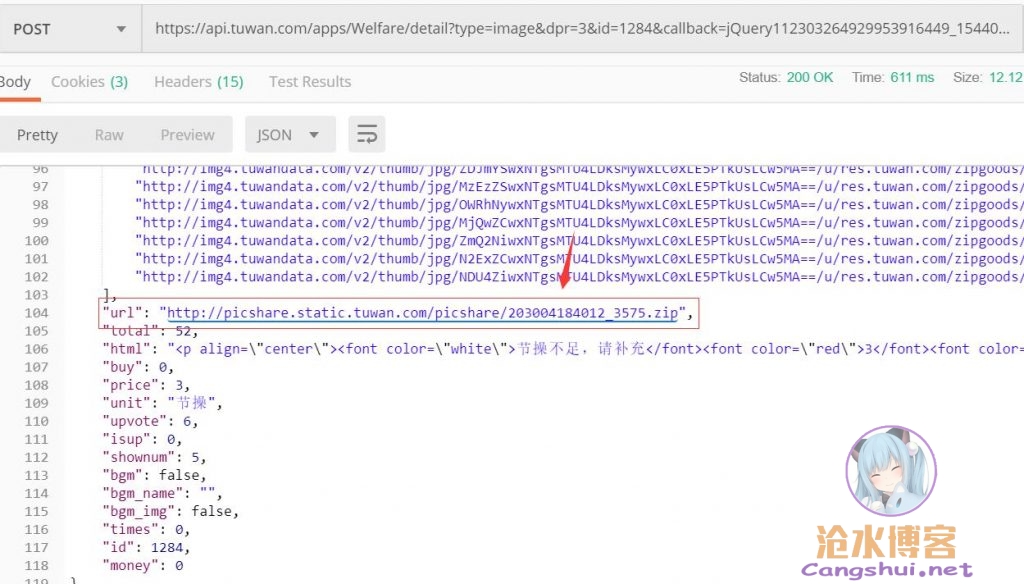
上下翻翻看,发现了一个神奇的链接,是个zip压缩包,嗯,有点意思。
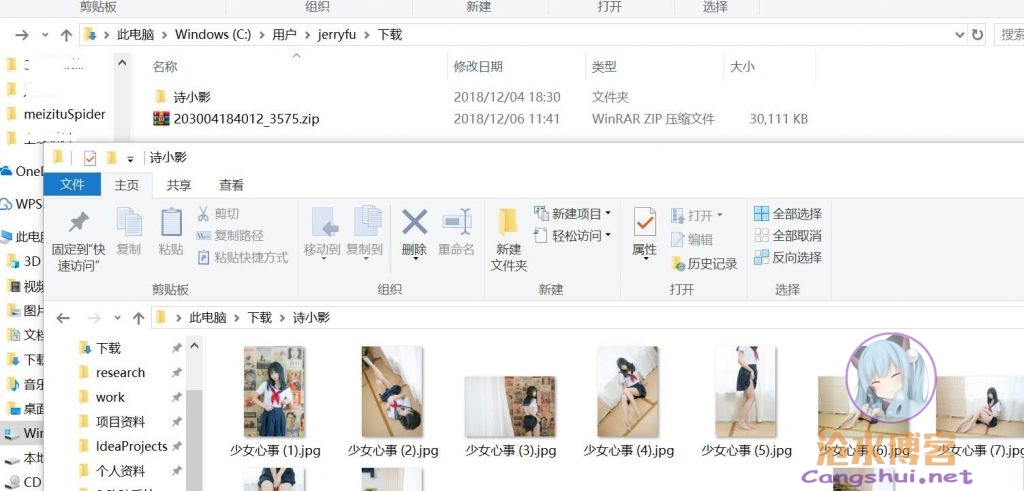
下载回来解压,哈哈,居然是该相册的所有照片。
看返回的结果,很明显使用了jsonp,于是接着试着减少参数,去除了返回结果中恼人的无用回掉前缀,最后简化到仅剩一个参数,id,这接口太呆萌了。
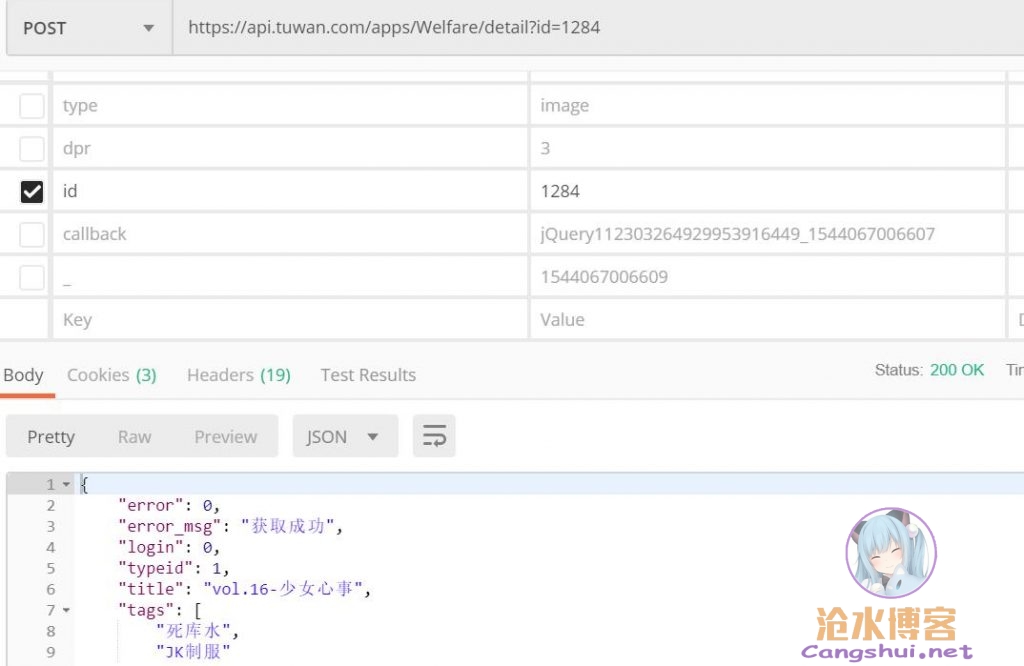
此外还发现了网页上音乐的地址。
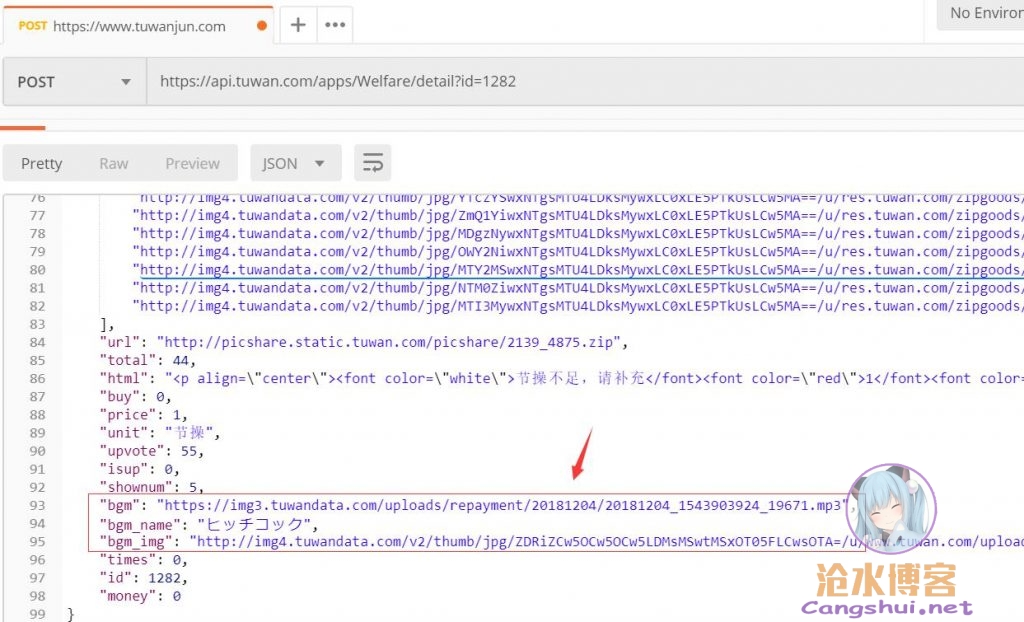
至此该网站的“核心资产”已经被扒的底裤都没了,2333,下面开始批量爬吧。
有两种思路,一种是利用主页调用的获取相册列表参数接口来获得相册列表再通过列表爬压缩包地址,另外一种是直接从1开始依次尝试到首页最新的一个相册对应的id。最终决定采用第二种思路,因为这样即使首页隐藏的相册通过这种方式也能被发现。
开搞,建数据库,数据表,为方便后续追加执行,以及放在服务器上爬,所以采用springboot配合异步调用来实现。一开始使用post方式进行调用,结果尝试抓取了一两百条后到数据库一看,怎么这么多重复的啊,而且怎么同一个id和我用postman直接调得到的结果不一致?很可能开反爬了。
转变思路,postman采用的是get方式,所以程序试试也使用get方式进行调用,同时加入线程随机睡眠时间和User-Agent请求头,以此模拟普通用户的浏览器访问行为。bingo,顺利的抓取到了正确的图包名称、下载地址地址、音乐名称、音乐下载地址等信息。
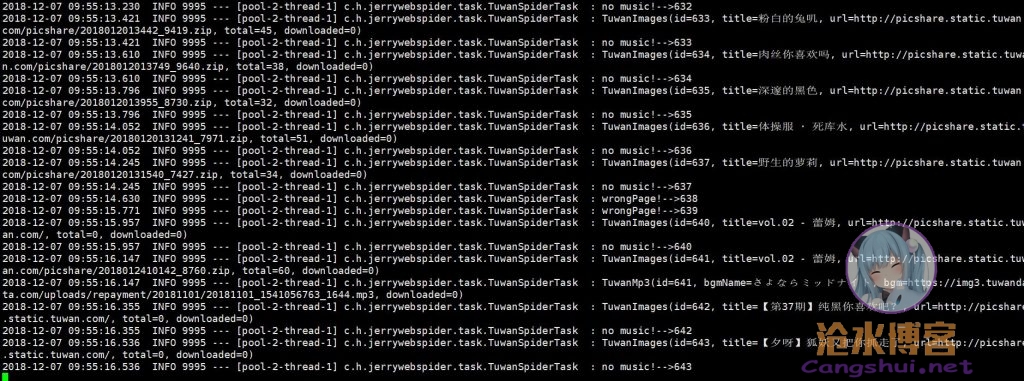
扔服务器上爬吧。等了大概十几分钟,爬完后总共获取到892条有效的图包记录,202条有效的音乐记录。
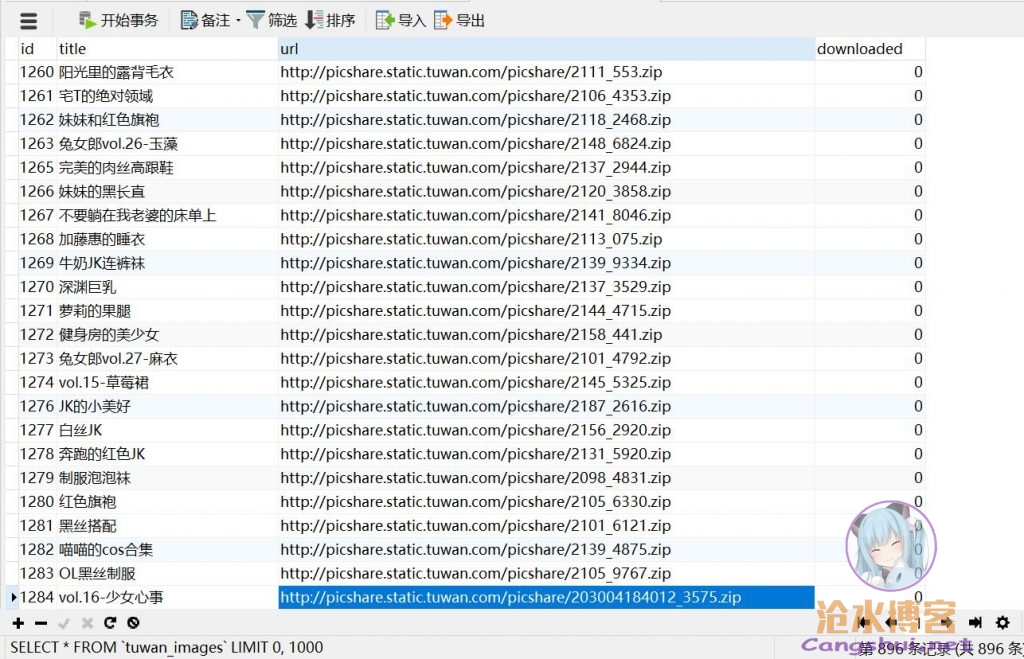
爬到地址后可不能算结束,还得把真正的压缩包都下载回来,写个批量下载的方法,服务器走起,然后便开始吭哧吭哧的下载,速度还行,能接近7MB/S。
从上午11点开始到晚上9点下载完成,总共耗时10个小时,从服务器上全部下载回来吧。

经过漫长的等待后,终于下载完,写了个脚本统计结果,最终:总共获取到了46187张图片,大小36.5GB。
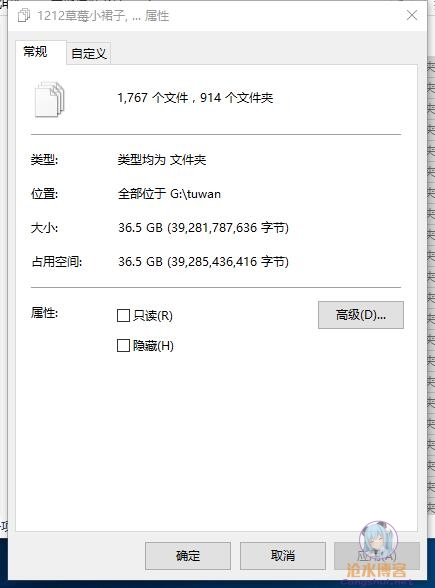

哇哦随机看看就看这个
“至此该网站的“核心资产”已经被扒的底裤都没了”233333333
真的不能订外卖吗
牛逼!
大佬牛逼(破音)
用的是百度云的,试了很多密码都不对啊。可以发下?
怎么抓彼岸图网上的图片
小姐姐图片?我有大量小姐姐视频。但懒得添加到我的视频采集站上。
资瓷dalao
自建网盘中的01A和02A链接好像有点问题呀,可以修复一下吗
我对图片不感兴趣,我对音乐感兴趣,→_→。
很强
我说,直接粘贴人家原文都不写点什么么
老哥,帅气
酷安观光团
酷安顶一下
服气服气
服气服气
666666
6666666
可以可以